
GTM Server-Side Pantheon - Part 2 - Supercharge Your Setup with Pub/Sub
In part 1 of this series about Google’s GTM Server-Side Pantheon I started taking you on a journey, during which we’ll discover how to integrate a variety of Google Cloud Platform (GCP) services into GTM Server-Side (sGTM). Sprinkled with references to Greek mythology, we explored how to integrate Firestore into GTM Server-Side and how businesses can enrich their data streams and, thereby, enhance their marketing strategies.
As you know, Firestore is excellent for gathering and storing data in real time, but in this post, I’d like to continue the journey with another powerful Google Cloud service: Pub/Sub. Pub/Sub takes us further than Firestore by enabling truly event-driven architectures and seamless cross-system communication. I’ll cover the basics of Pub/Sub, show you how to integrate it with GTM Server-Side, and show you how you can use this setup to power a real-time dashboard based on a GA4 data stream.
Note: Part 3 of this series focuses on how to use BigQuery and Google Sheets to further enhance your GTM Server-Side setup. You can read Part 3: BigQuery & Google Sheets integration
What is Pub/Sub?
At its core, Pub/Sub (short for Publish/Subscribe) is a messaging service GCP provides that facilitates the asynchronous exchange of messages between different systems. It’s designed to be highly scalable, reliable, and low-latency, enabling realtime communication between applications across various environments.
Think of it as an event-driven system where different components of a more extensive architecture can send messages without directly depending on or connecting to one another. Adding Pub/Sub as an intermediary step results in decoupling these services, making it a great fit for event-driven architectures.
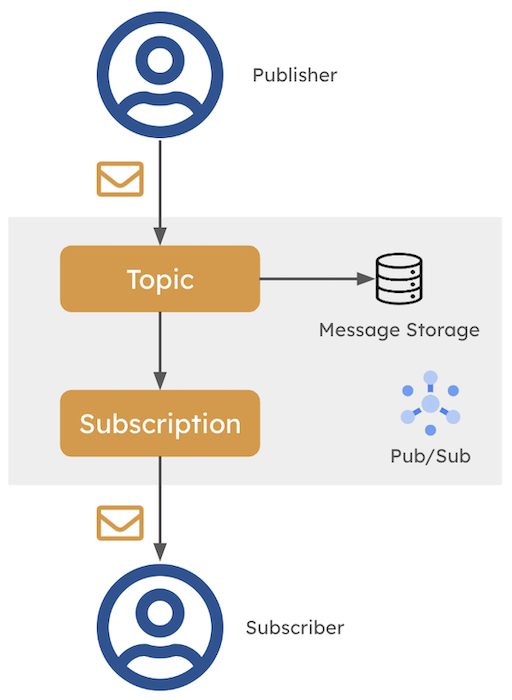 Lifetime of a Pub/Sub message
Lifetime of a Pub/Sub message
Here’s how Pub/Sub works:
- Publishers are entities that send messages (events or data) to a topic. These messages can be anything from user events to system logs. In the context of this blog post, sGTM acts as a publisher, sending events to a Pub/Sub topic.
- Topics are channels through which messages are exchanged. They act as mailboxes where publishers can drop messages and subscribers can pick them up.
- Subscriptions are the connections between topics and subscribers. They define the rules for how messages are delivered and processed.
- Subscribers are entities interested in receiving messages from a topic. They listen to the topic and can act on incoming data as needed. These can be anything from storing data in a database to triggering a Cloud Function—your imagination is the only limitation here.
Why send clickstream data to Pub/Sub?
Pub/Sub’s design characteristics make it ideal for handling high-velocity streams of user interaction data - such as your GA4, Piwik Pro, Amplitude, Mixpanel, etc. events. Once you’ve managed to route your clickstream data through Pub/Sub, you can have a wide array of GCP services, such as Cloud (Run) Functions, Cloud Run, DataFlow, or BigQuery, immediately consume the data without the delays of batch processing. These services can do so much more than what you can achieve within sGTM (and its available JS APIs). Naturally, this opens up a whole new world of possibilities for your clickstream data and what it can do for you. Let me give you a few examples:
- Realtime analytics: By sending your clickstream data to Pub/Sub, you can have it processed in realtime by services like DataFlow or Cloud Run. This allows you to get insights into your data as it happens, rather than waiting for batch processing.
- Triggering workflows: Pub/Sub can trigger workflows (e.g., a user just bought this, do that) and marketing automation processes (e.g., you, dear user, just purchased this, you might also be interested in…) based on specific events in your clickstream data.
- Writing to 3rd-party systems: If you need to send your clickstream data to a third-party system (e.g., your CRM), Pub/Sub can act as the intermediary that ensures the data is delivered reliably and efficiently (e.g., to update user profiles).
- + Whatever you can imagine: The possibilities are endless.
For example, an e-commerce website might use Pub/Sub to trigger different actions: a “purchase” event from the website could be dispatched to sGTM and published to Pub/Sub. Afterwards, several subscribers can consume the message, such as ML models, email marketing, and analytics systems, without needing these components to interact directly with each other.
Why use Pub/Sub instead of a direct API integration?
When building an event-driven system in the context of sGTM, one of the challenges is ensuring that it can efficiently handle traffic spikes (looking at you, Black Friday!) and message failures (maybe an event is missing required properties?). Now, a call directly to an API might seem like the easy way out, but it might make you go nuts in the long run because a direct integration lacks a critical feature: buffering.
I actually ran into this issue when wanting to write to Firestore to power a realtime dashboard in my first iteration (see further down for a more detailed walkthrough). While in scenarios of low traffic volume everything worked fine, the Firestore read & writes became a bottleneck when the traffic increased and as a result certain data points simply got dropped. I obviously wanted to ensure I got all the data points in my realtime dashboard, so I had to come up with a better solution.
In a high-throughput environment, where tracking data is constantly being generated, it’s essential to have a mechanism that can absorb the load if your downstream application is temporarily down, experiencing scaling issues, or quota limitations. This is where Pub/Sub’s key benefits come into play:
- Decoupling Services: Pub/Sub allows your system components to be independent of each other, increasing fault tolerance.
- Buffering: If there’s an issue with the downstream service (e.g., a crash or performance dip), Pub/Sub holds the messages until your application can catch up.
- Scalability: Pub/Sub is designed to scale automatically with the number of messages, ensuring the system remains stable even under high traffic.
- Reliability: Pub/Sub guarantees at-least-once delivery, ensuring that no message is lost in transit.
In short, Pub/Sub acts as an intermediary between your data producers and consumers - the downstream services -ensuring that your data is delivered reliably and efficiently, even under high-traffic conditions.
Now, you may think: “Okay, Gunnar, I get it; Pub/Sub is great, but how do I integrate it with GTM Server-Side?”
Hermes - The Messenger of the Gods
Well, let me introduce you to Hermes. Hermes is the messenger of the gods in Greek mythology. It is fitting that Google named their Pub/Sub GTM Server-Side custom template after him. The Hermes solution is a sGTM custom tag template that allows you to send event data in the form of messages to Pub/Sub.
How do you set up Hermes in GTM Server-Side?
Before you get started with the sGTM-Pub/Sub integration, make sure that you’ve created a Pub/Sub topic in your GCP project (GCP documentation) and that you have given the service account which your sGTM uses the roles/pubsub.publisher role.
Once this is in place, you can download the Hermes tag template from the GitHub repository, import it into your sGTM container, and create an instance of the Hermes tag:
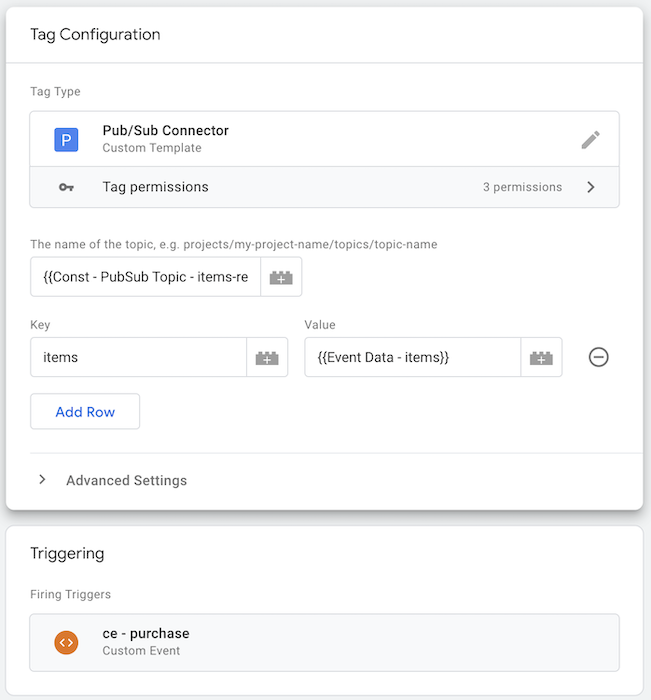 sGTM Hermes tag for Pub/Sub and sGTM integration
sGTM Hermes tag for Pub/Sub and sGTM integration
In the Hermes tag configuration, you need to:
- Specify the Pub/Sub topic you want to publish to. The format should be
projects/YOUR_PROJECT_ID/topics/YOUR_TOPIC_NAME. - Define the payload you want to send to Pub/Sub. Depending on the variables in your sGTM setup, this can be a static JSON object or a dynamic object.
The outcome from my example configuration in the screenshot will result in the Hermes tag sending the item data associated with each registered purchase GA4 event to my Pub/Sub items-realtime topic in the following format:
{"messages":[
{"data":
{
"items": [
{
"item_id":"123",
"item_name":"Blazer",
"price":150,
"quantity":1,
"currency":"DKK"
},
{
"item_id":"456",
"item_name":"T-Shirt",
"price":30,
"quantity":1,
"currency":"DKK"
}
]
}}
]}
And that’s it! You’ve successfully set up Hermes in your sGTM container, enabled streaming of your event data to Pub/Sub, and are ready to consume the data in downstream services.
How does Hermes work?
Let’s quickly take a glance under the hood of the Hermes tag template before we jump into the real-time dashboard example. Feel free to review the source code in detail yourself, but here’s a quick rundown of some of its core components/APIs:
- The tag uses the
getGoogleAuthto authenticate the sGTM instance with Pub/Sub. It uses the container’s service account to get the necessary credentials to authenticate requests to GCP services. So, grant this service accountroles/pubsub.publisherrights. This security measure ensures that only authorized users can publish messages to your Pub/Sub topics. - It builds the Pub/Sub message payload based on the configuration in the tag. Furthermore, the tag has some built-in type conversion based on the key name in your tag configuration (keys with suffix
_intare converted to integer, keys with_numare converted to number, otherwise it’s being interpreted as a string). - The payload is encoded to base64 (using
toBase64) to ensure the data is transmitted consistently. This also means that you have to make sure to decode the message’s data in the subscriber. - Eventually, the tag uses the
sendHttpRequestAPI to send the message and its payload to Pub/Sub.
Using GTM Server-Side and Pub/Sub to power a real-time dashboard
Now, let’s put our newly acquired knowledge to use and apply it to a real-world example.
The idea is to build a realtime dashboard that monitors detailed information about user purchases on a given website. The dashboard will report on the total revenue and the number of items sold and provide a detailed breakdown of each item sold. Something that you currently can’t do with GA4’s built-in reporting.
This could be particularly useful for e-commerce websites, where you want to keep a close eye on your sales performance and want to make fast decisions - especially during high-traffic events like Black Friday.
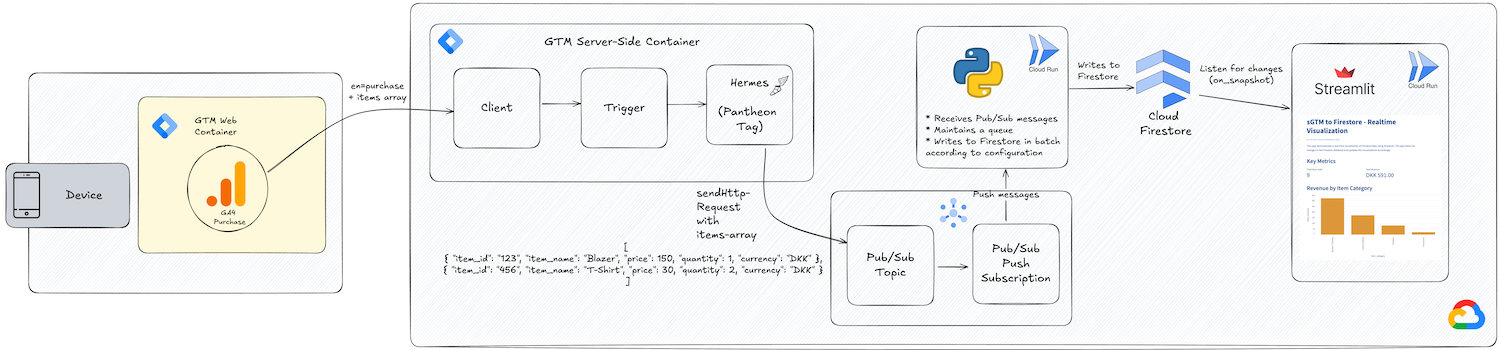
The architecture consists of the following components:
-
GTM Web Container: A client-side GTM container for managing GA4 tags. In this case, it captures
purchaseevents with associated item data (likeitem_id,item_name,price,quantity,currency, etc.). - sGTM Container:
- Client: Receives the data from the GTM web container (such as purchase and item information), parses it, and makes it available to the container assets.
- Hermes (Pantheon Tag): This tag forwards the items array to the Google Pub/Sub topic for further processing.
- GCP Pub/Sub:
- Topic: Acts as a messaging queue where the item data from sGTM is published.
- Push Subscription: Pushes/forwards the messages as they arrive from the topic to a Cloud Run service for processing.
- Event Consumer Application (Cloud Run): A serverless compute platform where a Python application is running. This service:
- Receives Pub/Sub messages (the item arrays).
- Maintains a queue to process these messages.
- Writes the processed data into Firestore in batches.
-
Firestore (optional): A NoSQL document database where the processed data from Cloud Run is stored (and can be used in future look-ups from sGTM). If you don’t need to persist the data in Firestore, you could skip this step and combine the processing and visualization in the same Cloud Run service.
- Real-Time Dashboard Application (Cloud Run):
- It listens for changes in real-time (using
on_snapshot) and triggers updates accordingly. - Streamlit web application framework that visualizes realtime data. In this case, it displays key e-commerce metrics (e.g., total revenue) based on the purchase data stored in Firestore.
- It listens for changes in real-time (using
Let’s double-click on some components in the following sections to understand how they work together.
Pub/Sub Push Subscription and Cloud Run
Pub/Sub has two main types of subscriptions: pull and push. Pull subscriptions require the subscriber to actively request new messages from the Pub/Sub topic, while push subscriptions automatically deliver messages to a specific subscriber application. In my case, I opted for a Push Subscription for the following reasons:
- Simplicity: Because of the push subscription, there’s no need to manage an additional polling mechanism. Instead, all messages are delivered automatically to the Cloud Run service as they hit the topic.
- Latency: Push subscriptions are (almost) real-time, reducing the delay between message publication and processing. This is crucial for my real-time dashboard.
- Scalability: Combining the push subscription with a serverless, auto-scaling Cloud Run infrastructure relieves me of managing the infrastructure.
Since we are using a Pub/Sub push subscription, Cloud Run will provision instances only when necessary. GCP’s pay-as-you-go pricing model, where we pay only for actually used resources, helps keep costs at bay.
The main functionality of the Cloud Run application is to process the incoming messages from Pub/Sub and write them to Firestore. The application is written in Python and uses the google-cloud-firestore library to interact with the database.
from google.cloud import firestore
# Update Firestore
for item_id, count in item_counts.items():
item_ref = db.collection('items').document(item_id)
batch.set(item_ref, {
'counter': firestore.Increment(count),
'item_name': item_details[item_id]['item_name'],
'price': item_details[item_id]['price'],
'currency': item_details[item_id]['currency'],
'item_id': item_details[item_id]['item_id'],
}, merge=True)
# Commit the batch
batch.commit()
As you can see from the above code excerpt, the application uses batch writing to update the Firestore collection with the item data captured for each purchase event on the website. The update is done in batches to ensure that the data is written efficiently and to avoid hitting Firestore’s write limits.
Firestore collection structure
The outcome is a Firestore collection that holds a document for each item. Each item then has a counter attribute that is increased by the quantity of the item in the associated GA4 purchase event (using firestore.Increment() as shown in the above code snippet) and additional product information (e.g., price, item_category, profit, etc.):
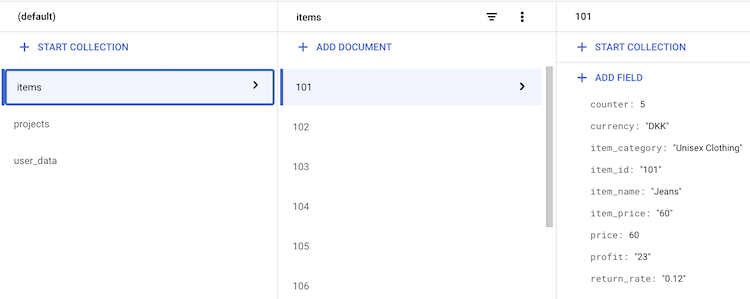 Firestore document structure for realtime dashboard
Firestore document structure for realtime dashboard
Real-Time Dashboard
Now, that the data is ready to be consumed and visualized, the dashboard application fetches the initial state of the Firestore data and attaches a listener to the Firestore collection. The dashboard itself is built with Streamlit for Python, a framework that allows you to create interactive data visualizations with having to deal too much with HTML and CSS. Pandas is used to process the data in dataframes, and Altair is used to create the visualizations.
The following code snippet shows the core of the application - how it fetches the initial state of the Firestore data and sets up the real-time listener:
from google.cloud import firestore
import pandas as pd
# Initialize Firestore client
db = firestore.Client()
# Function to fetch data from Firestore
def fetch_items():
items_ref = db.collection('items')
docs = items_ref.stream()
data = []
for doc in docs:
item = doc.to_dict()
item['item_id'] = doc.id
data.append(item)
df = pd.DataFrame(data)
# Convert 'item_price' and 'counter' to numeric, replacing non-numeric values with NaN
df['item_price'] = pd.to_numeric(df['item_price'], errors='coerce')
df['counter'] = pd.to_numeric(df['counter'], errors='coerce')
return df
# Set up the real-time listener
items_ref = db.collection('items')
doc_watch = items_ref.on_snapshot(on_snapshot)
# Initialize dataframe
df_items = fetch_items()
When the on_snapshot() function is executed, a persistent connection to the item data in the Firestore database is established. Now, whenever a document in the items collection is added, modified, or deleted, the on_snapshot() function will be automatically called with information about the changes.
This is the key to realtime updates in this application. It allows the app to react immediately to any changes in the database without constantly polling for updates—that is, whenever a GA4 purchase event is registered.
Note: When you use the
on_snapshot()callback function with Streamlit, the function is executed in a sub-thread, while UI manipulation (e.g., updating the visuals) in Streamlit must happen in a main thread. In the Further Reading section, you can find a link to a Google blog post that explains how to handle this situation.
After assembling all the bits and pieces, the dashboard eventually displays the total profit, the number of items sold, and a table with detailed information about each item. In the video above, you can see the dashboard in action.
You can find the full code for the Cloud Run application and the Streamlit dashboard in this GitHub repository.
Conclusion
And that’s it - you made it! I hope you enjoyed the second part of our journey through the sGTM Pantheon focus, which focused on integrating your client-side clickstream data with GTM Serve-Side and Pub/Sub.
By integrating Pub/Sub with sGTM, you can unlock new use cases and expand the capabilities of your data collection and processing. Whether you need to trigger downstream processes, send events to third-party systems, or store data for further analysis, Pub/Sub provides the flexibility and scalability to meet your needs.
In the next part of this series, we’ll most likely looking into how to use BigQuery and Google Sheets to further enhance your GTM Server-Side setup. Stay tuned - it ain’t over just yet!
As always, if you have any questions or are interested in dicussing a specific use case, feel free to reach out to me on the channels listed on this website.
Until next time, happy tracking!
Further Reading
If you’re interested in learning more about Pub/Sub and how it can be used with GTM Server-Side, check out the following resources:
- Use Google Tag Manager Server-Side for Visitor Stitching by Querying a GCP Database in Real-Time by Lukas Oldenburg
- Activating GA4 events with GTM Server-Side and Pub/Sub for Fun and Profit by Mark Edmondson
- Building a Mobility Dashboard with Cloud Run and Firestore by Google Cloud
Book a meeting with me: Calendly