
GA4 - The CDP You Didn't Know You Had
This article is a write-up of my talk at MeasureCamp Czechia in Prague in September 2023 - thanks to everyone who attended the session and provided feedback.
I’ll explore how Google Analytics 4 (GA4) can be used as a lightweight Customer Data Platform (CDP) and how it can be integrated with other tools to create a powerful data activation stack. Furthermore, I’ll also discuss the current state of GA4 and the challenges faced by GA4 users. Lastly, I’ll highlight some of the recently added powerful GA4 features like the Audience Export API and User data exports to BigQuery and how they can be used to build a use case-specific data activation stack (or “Customer Data Platform (CDP)” if we want to join the buzzword bingo).
Walk Down Memory Lane - History of Google Analytics
First let’s take a step back to put the recent developments into perspective and look at some high-level context. Google Analytics (GA) has come a long way since its inception in 2005. Back then, GA was a simple JavaScript snippet that allowed website owners to track pageviews and gain insights into their website’s performance. Over the years, GA has evolved into a sophisticated analytics platform that offers a wide range of features and capabilities.
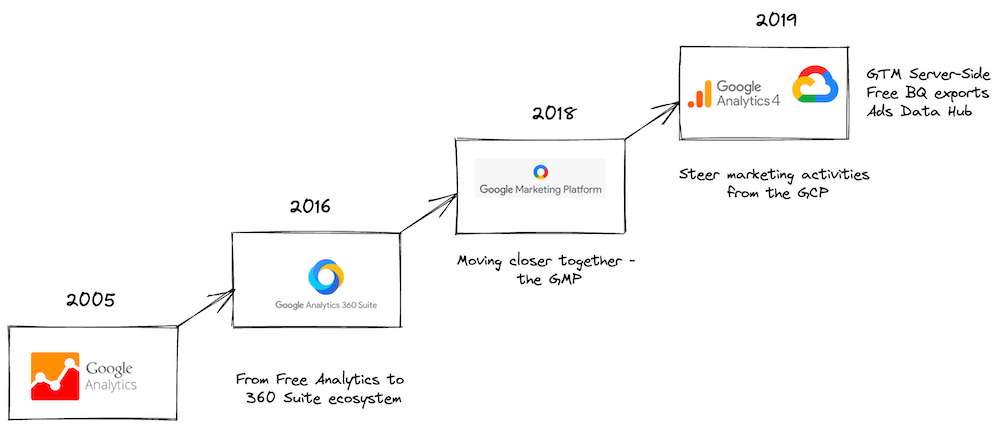
In March 2016, Google introduced Google Analytics 360, a premium version of GA that offers additional features and support. In 2017, Google launched Google Analytics for Firebase, a free analytics solution for mobile apps. And in 2018, Google re-strucutred its marketing platform, which resulted in GA becoming a part of the Google Marketing Platform (GMP). In the GMP, GA takes the role of a central measurement platform able to share audiences and conversions with the marketing tools in the platform to help optimize ad budgets. In 2019, Google announced Google Analytics 4, a new version of GA that offers a more unified approach to analytics across platforms and devices, which replaced its predecessor Universal Analytics (UA).
Google built GA4 on the foundation of Google Analytics for Firebase, and since allows users to combine data from websites and mobile apps into a single property. Moreover, GA4 made former 360-features part of its free version, such as BigQuery export, data-driven attribution, and more. The arrival of GA4 also marked a shift in how Google thinks marketers should approach analytics and data activation, as it sets a stronger focus on the Google Cloud Platform (GCP) and its capabilities. BigQuery is considered the centerpiece of this new approach, as it allows users to export raw data from GA4 and use it for advanced analyses - oftentimes being the only way to overcome limitations imposed in GA4’s interface (e.g., limits due to cardinality or privacy restrictions). At the same time, other solutions which are tightly integrated with GA4 and harness the capabilities of the GCP evolved, like Google Tag Manager Server-Side, which allows users to send data from their website to GA4 via the GCP (or any other cloud provider).
The Current State of GA4 and Challenges Faced by GA4 Users
While Google touted GA4 as a revolutionary step forward in analytics, it’s important to acknowledge the platform’s various shortcomings that have made it difficult for the community to fully trust and utilize the data it provides. Many users (including me) have felt like guinea pigs, navigating and debugging a flawed tool on behalf of Google’s product team with minimal support and missing documentation. This has led to a significant amount of lost trust and time being spent on troubleshooting — trying to discern whether issues arose from setup errors or inherent bugs within the tool itself. The situation is exacerbated when you compare the learning curves of GA4 and UA. While UA had a steady, albeit less steep, learning curve, GA4’s has been steeper and less well-supported, both by Google and the broader analytics community since it simply was a new tool nobody had any experience with.
The plentitude of blog posts addressing specific issues with GA4 and its usability is a testament to the tool’s current shortcomings. See below for a few selected examples:
- The Traffic Source Challenge in GA4 (by Charles Farina) explains how a supposedly simple question like “How many users visited your site?” can be difficult to answer in GA4.
- GA4 sessions magick. Which hit makes a session source / medium? (by Artem Korneev) explores how GA4’s sessionization logic, which is not inherent to GA4’s data model, works and how it can lead to unexpected results.
- How Do I Access The Individual Timestamp Of A GA4 Event? (by Simo Ahava) explains how GA4’s tracking library attempts to batch events together and how this makes it impossible (without a workaround) to access the individual timestamp of a GA4 event.
- Lastly, Dear Google Analytics 4 (by Simo Ahava) is a letter to Google Analytics 4, where Simo Ahava shares his thoughts on the current state of GA4 and the challenges it poses to users.
All of this, has made it challenging for users to focus on data analysis and activation, rather than getting bogged down by the tool’s limitations. However, it’s important to note that GA4 is still in its infancy (which it obviously shouldn’t be anymore) and that Google is working hard to improve the tool - which is proven by the frequent feature releases and improvements.
That said, no platform is without its challenges, whether it’s data migration issues or problems with integrating other tools. Despite these hurdles, the focus of this blog post is to explore recently added GA4 capabilities and the “cool” stuff you can do with the tool. I truly believe it’s about time to stop working the tool and rather start exploring what the tool can do for us!
So, while it’s crucial to be aware of these issues, let’s dive into the capabilities that GA4 and its deeper integration into the GCP bring to the table.
Recently Added Powerful GA4 Features for Data Activation
User Data Export to BigQuery
In your journey with GA4, you have probably already come across the BigQuery Export feature that allows you to export (almost) raw-level event data (if not, I strongly recommend checking it out). In August 2023, Google added the option to include a daily export of user data, which is then organized into two distinct tables within your BigQuery project under the same dataset as the events_* and events_intraday_* tables.
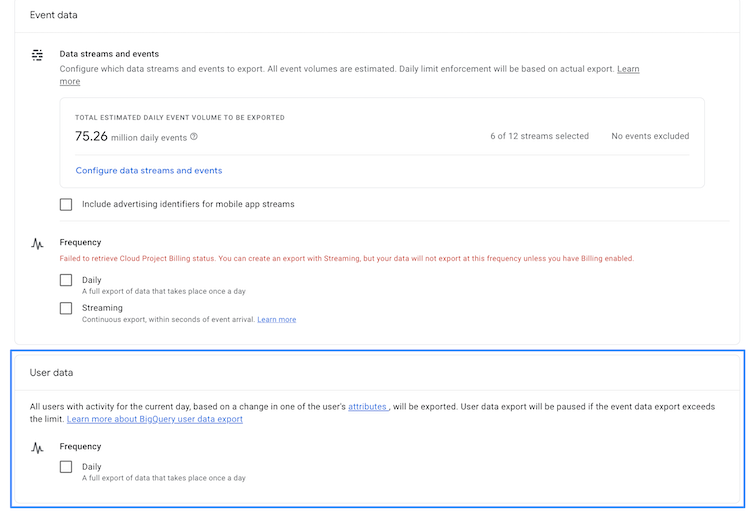 Source: Google Documentation
Source: Google Documentation
The first table, labeled pseudonymous_users_* contains a row for each pseudonymous identifier and is updated whenever there’s a change in one of the fields. Importantly, this table does not include data for unconsented users or export user IDs, but it does include the last active timestamp for each pseudo ID. The second table, users_* focuses on user-specific data, updating similarly when there’s a field change. Unlike the Pseudo ID table, this one can include data for unconsented users if a user ID is present (which might be considered somewhat problematic from a privacy perspective).
Both tables include any user whose data has changed that day. This could be due to a new session initiation or even being dropped from an audience for not meeting certain conditions, like not making a purchase in the last 7 days. For more information on how to work with these datasets, check out Google’s query cookbook.
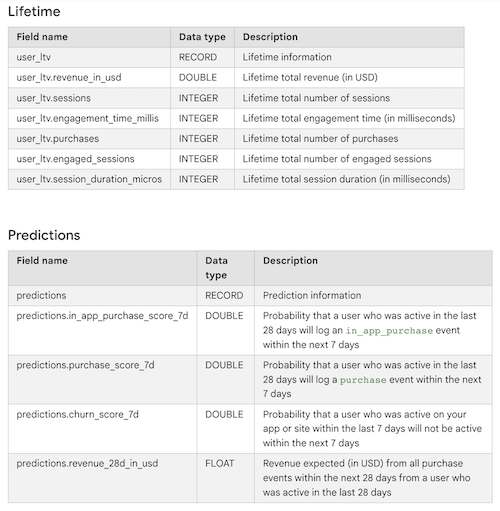 Source: Google Documentation
Source: Google Documentation
While the exports contain a lot of expected data points like user properties, device information, and geo data, I am mostly hyped over the Audiences, Lifetime and Predictions fields.
The Audiences fields allow you to query a list of User or User Pseudo IDs that are part of a specific audience. This is a great way to save time when attempting to recreate complex audience definitions from the GA4 Audience Builder in BigQuery. Previously you had to export the audience definitions from the GA4 UI and then recreate the actual audience in BigQuery. Now you can simply query the audiences.id or audiences.name fields and get a list of User or User Pseudo IDs that are part of a specific audience. Furthermore, you might want to share these IDs with other tools in your data activation stack, like a CRM or a DMP.
The Lifetime fields contain user-level totals for revenue, engagement time, numer of purchases, etc.. This is super helpful if you plan to apply behavioral segmentation techniques to your data. Essentially, you can use these fields to create a user-level RFM (Recency, Frequency, Monetary) model, which can be used to identify your most valuable customers and create personalized experiences for them.
Lastly, the Predictions fields contain user-level predictions for the likelihood of a user to perform a specific event. This is a great way to identify users that are likely to perform a specific action, like making a purchase, and then target them with a specific message or offer. Again, having this data at your fingertips out of the box saves you the time and effort of recreating these predictions in BigQuery using BigQuery ML or building out your own pipelines using something like Vertex AI.
Please be aware that at this point of time the exports seem to include data from just a subset of the site’s actual visitors though (a typical Google release?). So, this feature does not seem to be fully functional yet. But eventually these exports will hopefully reduce the effort to obtain audience data significantly and enable the use cases mentioned above.
Audience Export API
With GA4, Google introduced a new Audience Builder that allows you to create complex audiences based on a wide range of conditions and much more flexible than what you could do in UA. While this was a great step forward, it still was a rather cumbersome process to export these audiences to other tools in your data activation stack, which is why only very few companies did it in the first place. Out of the box, you could export audiences to Google Ads and other GMP tools, but that was about it.
 Source: LinkedIn
Source: LinkedIn
In June 2023, the Audience Export API was released and coined as “one of the most transformative API releases in the history of GA”. The reason for this is that the introduction of this API marks a strategic shift for GA from being a data silo to a data activation platform. The API allows you to export audiences to other tools in your data activation stack, and use them to create personalized experiences for your users. Early adopters of this functionality are third-party A/B testing tools like Optimizely, VWO, or AB Tasty. These tools allow you to create personalized experiences for your users based on the audiences you created in GA4. For example, you could create an audience of users that have not made a purchase in the last 7 days and then target them with a specific offer or message.
Working with GA4 Audience Lists
The following process illustrates how you can use the Audience Export API to export audiences to any tool or platform of your liking:
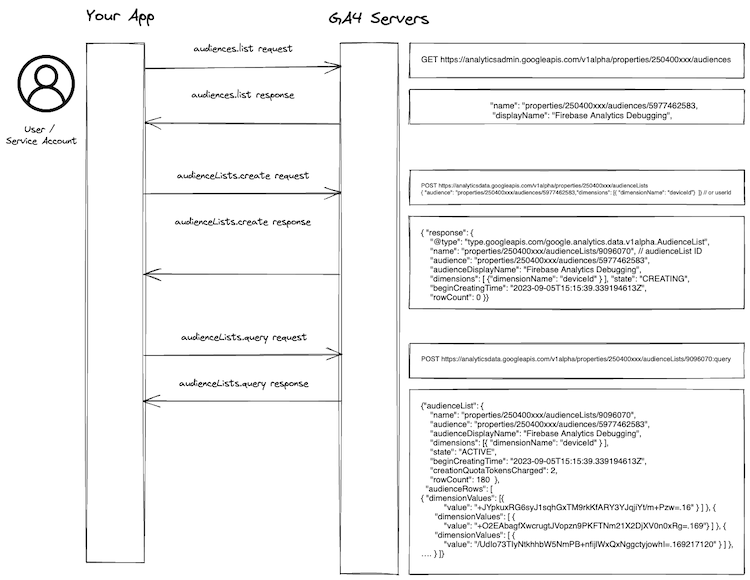 Source: Own visualization and Audience List Fundamentals documentation
Source: Own visualization and Audience List Fundamentals documentation
Audiences allow you to group users based on shared attributes, providing a more targeted approach to data analysis and marketing. The API enables you to create Audience Lists asynchronously, offering snapshots of users within a specific audience. You can initiate this by making a POST request to the audienceLists.create method, followed by querying the list using audienceLists.query. Metadata and configurations can be retrieved using audienceLists.get, and you can view all Audience Lists for a property with audienceLists.list.
The API requires the GA4 property identifier in the URL request path. The Audience List creation process requires specific parameters, such as a valid audience name and one dimension (userId or deviceId). Once created, it may take several minutes for the Audience List to be generated, and you can check its readiness state using audienceLists.get.
GA4 Audience Lists Limitations
Audience Lists identify users by User ID or Device ID, regardless of the reporting identity setting in GA4. This means that the number of users in your reports can differ from those in your Audience Lists. Also, unlike Google Ads remarketing, Audience Lists do not contain backfilled audience memberships. Users need to log an event after the audience is created to appear in new Audience Lists.
It’s important to note that Audience Lists are snapshots in time and do not automatically update. They have a data freshness period, typically averaging 24 hours, and expire after 72 hours. If you need updated lists, you’ll have to create new ones. Additionally, there are user limits depending on your property type, affecting the maximum number of returned and considered users.
So, while the process has its intricacies, the ability to create and query Audience Lists in GA4 offers a powerful tool for businesses looking to understand and engage their user base more effectively.
GTM Server-Side Firestore Integration
The Google team has recently rolled out asynchronous variables in Google Tag Manager Server-Side (sGTM), opening up new avenues for data enrichment. Adding to this the team introduced a new Google Cloud Platform API for sGTM — Firestore. This NoSQL, scalable database is designed for near-real-time write/read operations. To simplify data retrieval, sGTM now includes a Firestore Lookup variable, allowing you to pull values from specific keys or fields in a Firestore document to enrich data streams routed through sGTM.
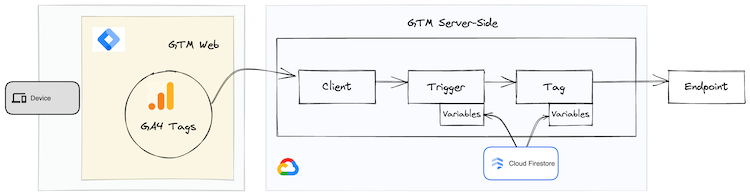 Source: Own visualization
Source: Own visualization
Firestore’s potential for data enrichment is vast. You could for example build a flow that powers Value-Based Bidding in Realtime to enrich Google Ads data in real-time. “Simply” use the Firestore Lookup variable to retrieve products’ profit margin from a Firestore document and then send it to Google Ads via a server-side conversion event. This allows you to adjust your bids in real-time based on the purchased products’ profit, which is a great way to optimize your ad spend.
In the context of this blog post, we might want to use the Firestore Lookup variable to enrich GA4 data with the outcome of cloud-based data modelling. For example, we could use the Firestore Lookup variable to retrieve a user’s lifetime value (LTV) or its RFM segment from a Firestore document and then send it to GA4 via a server-side event. This allows us to use this data as an input for even more valuable segment/audience definitions, which we then can activate through the Audience Export API or the User Data Exports.
GA4 as a Lightweight Composable CDP
Now that we’ve explored some of the recently added powerful GA4 features, let’s take a step back and look at the bigger picture. As mentioned in the introduction, GA4 allows you to combine data from websites and mobile apps into a single property, which is a great step forward. However, GA4 is still a measurement tool at its core. That said, GA4 can become the centerpiece of a data activation stack.
Putting Together the Building Blocks
To achieve this, we need to combine GA4 with GCP capabilities that allow us to orchestrate data flows and build out our own data pipelines. The following diagram illustrates how we can piece together the previously mentioned features to create an engine that’s able to power a wide range of data activation use cases:
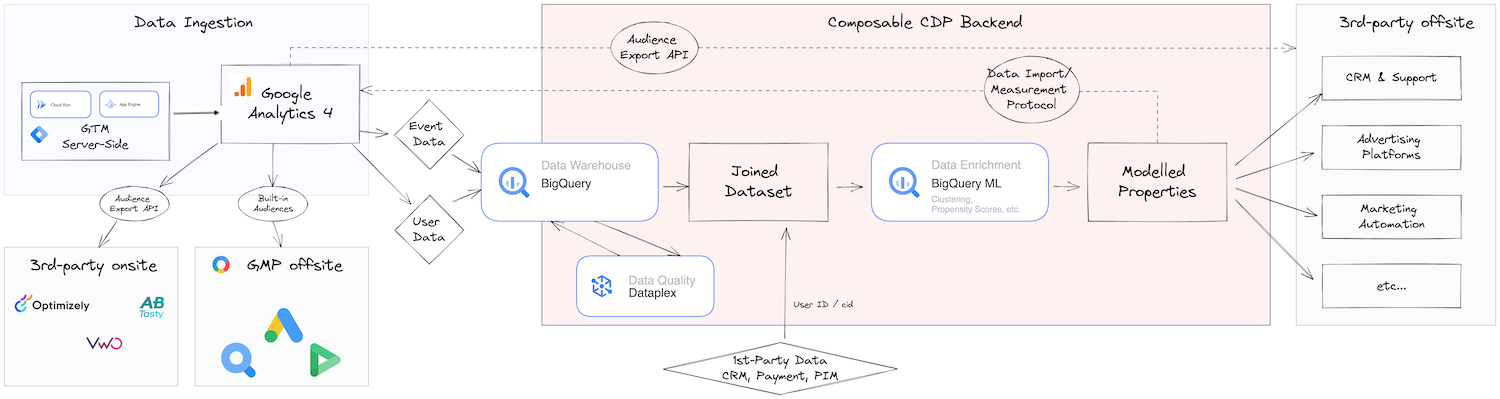 Source: Own visualization
Source: Own visualization
The core elements of the proposed architecture can be summarized as follows:
| Component | Purpose | Google Feature |
|---|---|---|
| Behavioral Data Collection | Collect behavioral data or event data from first-party data sources | gtag.js, Google Tag Manager (GTM), Firebase SDK |
| Data Ingestion: ELT (or ETL) | Extract all types of data from a growing catalog of secondary data sources | GA4 User Data & Raw Data Export, and BQ Data Transfer Service (Google Ads, DV360, etc.) + others (e.g. Fivetran) |
| Data Storage/Warehousing | Centerpiece to which all other components connect to | BigQuery |
| Identity Resolution and Profile API | Unifying user records captured across multiple sources | GA4 User ID (deterministic) + others (based on needs) |
| Visual Audience Builder (and Data Modeling) | Drag-and-drop interface to build audiences or segments by combining data from various sources | GA4 Audience Builder |
| Reverse ETL | Moving data from the data warehouse to downstream destinations | Audience Export API + others (e.g., Hightouch) |
| Data Quality | Ensure that the data powering their CDPs is not funky | DataPlex, Dataform + others (based on needs) |
| Data Governance and Privacy Compliance | Set up governance checks and compliance workflows | GA4 Data Controls, Consent Mode + others (based on needs) |
Source: Composable CDP vs. Packaged CDP + Own interpretation of available GA4 & GCP features
The architecture components outlined here closely resemble the modular nature of a Composable CDP. In a Composable CDP, each component is designed to perform a specific function and can be easily interchanged or augmented. For example, the “Data Ingestion: ELT (or ETL)” and “Visual Audience Builder (and Data Modeling)” components in this architecture can be tailored to integrate a variety of data sources and modeling tools, offering the adaptability that is a hallmark of Composable CDPs. The “Reverse ETL” component ensures that data can flow not just into, but also out of the data warehouse, enabling a dynamic, two-way data exchange with other platforms. This modular approach adapted by GA4 allows for greater flexibility and scalability, making it easier to adapt to evolving business needs and technologies and in a lot of cases might be able to cover the role of a dedicated Reverse ETL tool.
Orchestrating Data Flows with GA4 and GCP
As you can see from the above, GA4 can be used to orchestrate data flows between various tools in your data activation stack. For example, you obviously could use enriched GA4 data to export audiences to Google Ads and DV360, and then use these audiences to create personalized experiences for your users. At the same time, you could use GA4 to export audiences to BigQuery via the User Data Export or via a direct integration with the Audience Export API, and then use these audiences to create personalized experiences for your users in your CRM or Email Marketing platform. Moreover, you could use GA4 to export audiences to BigQuery, enrich the behavioral data with first-party data from the CRM, Payment System, etc., share it with the desired ad platforms, and then use these valuable audiences to tailor your messaging towards them. As you can see, the possibilities are endless, and it’s up to you to decide which use cases are most relevant to your business.
GA4 opening up its boundaries and allowing you to use its powerful features (e.g., Predictive Metrics) to inform third-party systems really is a game-changer and should change the way we think about GA4, as it is now able build out CDP use cases with minimal overhead and without the need to buy into additional tooling. This combined with lowered entry barriers to machine learning techniques (using e.g. BQML for clustering and/or prediction) makes advanced use cases with the potential to yield actual business outcomes much more accessible to a broader range of companies.
Conclusion
In conclusion, Google Analytics 4 (GA4) is evolving into a robust platform capable of serving as the centerpiece of a data activation stack. However, it’s important to note some limitations. One significant shortcoming is the lack of real-time support; both the Audience Export API and User Data Export features are updated only on a daily basis, which may not meet the needs of businesses requiring real-time data activation. Additionally, the complexity of integrating these new features means that businesses will need a capable data team to stitch all the requisite components together, which can be a significant undertaking.
As for areas of improvement, GA4 could benefit from more powerful Data Import features, perhaps through an API. The current method of importing data via an SFTP server is cumbersome and less than ideal. Furthermore, it would be advantageous if BigQuery could serve not just as an export destination but also as an import source for GA4, streamlining the data flow between platforms.
Despite these challenges and areas for improvement, GA4’s recent feature additions and deeper integration with the Google Cloud Platform signify a strategic shift towards becoming a more open and versatile platform. These features empower businesses to enrich their data and integrate GA4 with a variety of tools, enabling a wide range of data activation use cases that go beyond traditional analytics. As GA4 continues to mature, its expanding role in data activation is defnitely something to keep an eye on if your using GA4.
Feel free to reach out to me, if you want to explore GA4’s CDP capabilities for your business!
Book a meeting with me: Calendly
