
GTM Server-Side Pantheon - Part 4 - Bringing AI to sGTM
Welcome to the grand finale of our mythological journey through the GTM Server-Side (sGTM) Pantheon! In this fourth and final part on this topic, we’re reaching for the Olymp once again by bringing Google’s AI and predictive capabilities into your sGTM environment.
Since September, our journey through Google’s Pantheon has already covered some ground. We began by exploring Firestore-based templates (Artemis, Soteria, Hephaestus) - a topic that resonated strongly with you and remains the most popular post from the series to date. I highly recommend starting there if you haven’t read the article yet.
From there, we moved on to Pub/Sub (Hermes), uncovering how Google Cloud’s (GCP) messaging service can trigger downstream processes from your sGTM setup. Our most recent stop examined the integration of BigQuery for clickstream data analysis (Chaos), alongside the implementation of reading and writing selected data points to Google Sheets (Apollo).
Now, we’re (or mainly me in this case) ready to finish this series with perhaps its most exciting set of services yet. If you’ve dabbled in machine learning (ML) within GCP, you’re likely familiar with Vertex AI - Google’s ML platform for training and hosting models. And unless you’ve been living under a rock, you’re aware of the buzz around Large Language Models (LLM), Generative AI (GenAI), and Google’s version of it - Gemini.
In this final chapter, we’ll look into how to use these AI tools within your sGTM measurement hub, transforming your data collection infrastructure into an “AI-powered insights engine” (sounds cool, right?). Let’s check out how the Phoebe (Vertex AI integration) and Dioscuri (Gemini integration) solutions from Google’s Pantheon can be used.
What is Vertex AI?
Before I walk you through the details of bringing predictive services into sGTM, let’s have a look at GCP’s ML suite. Vertex AI is Google’s centralized platform for machine learning and AI—think of it as your go-to solution for training, deploying, and managing ML models and AI applications. This is where data science meets cloud infrastructure, meaning in here you can turn your models into scalable, production-ready solutions.
Google’s platform combines various ML capabilities, from no-code solutions like AutoML (perfect for those who don’t need to customize their models highly) to full-blown custom training options and MLOps for ML professionals. What makes it interesting for our sGTM context is its ability to serve predictions in real time through API endpoints—a capability we’ll utilize with our Phoebe solution.
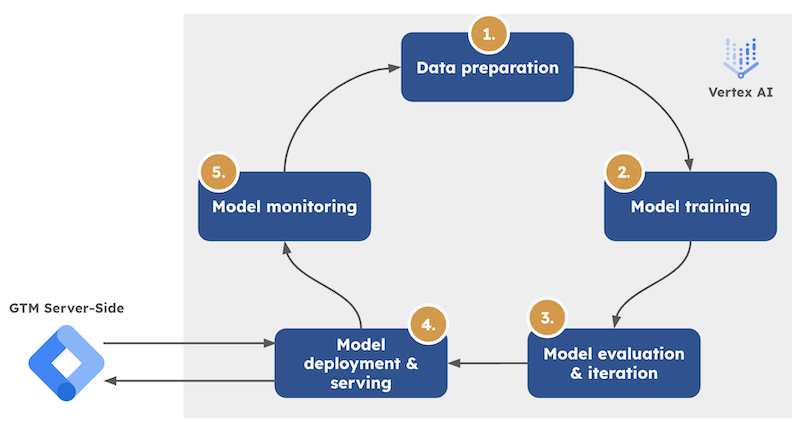 Vertex AI and sGTM
Vertex AI and sGTM
Vertex AI also houses Google’s generative AI models (Gemini) and provides the infrastructure to tune and deploy them. This is where the Dioscuri solution comes into play.
For now, imagine Vertex AI as the backstage area of your AI operations - it’s where all the magic happens before your ML or LLM models enter your sGTM setup.
Phoebe - The Goddess of Predictions
In Greek mythology stories, before the Age of the Olympians, there was the Golden Age of the Titans. Titans were the personifications of the universe’s elements and cosmic forces. So, Phoebe, the Titan goddess of prophecy (=prediction) and intellect, can be considered even more potent than her Olympian descendants. Choosing this name to access a powerful tool like Vertex AI via sGTM is quite fitting (although I know that many of you find the mythology references Google chose to be ridiculous).
Value-based Bidding as the default use case
Suppose you’ve read the Firestore integration section. In that case, you know how value-based bidding (VBB) can help you level up your marketing platform bidding from revenue optimization to profit optimization based on custom conversion values (e.g., profit margin) stored in Firestore.
However, there is one significant limitation: The values need to exist in Firestore before conversion happens. This static approach works well for most scenarios, but what if we need something more dynamic? Something that could calculate values on the fly based on real-time clickstream data?
This is what the original Phoebe use case is about (read more about Phoebe on GitHub). The solution variable template enables real-time predictions from Vertex AI models directly within your sGTM setup. Let’s take a glance at how this works:
- It starts with your standard GTM web container setup, configured to capture purchase events.
- When a purchase occurs on your site, the e-commerce event data (including revenue and item data) gets dispatched to your sGTM container.
- In sGTM, a custom variable in your Google Ads tag (triggered by these purchase events) makes a real-time call to your Vertex AI model endpoint. This model processes the event data and returns a prediction.
- Finally, this predicted value replaces the original conversion value before the event data gets passed on to your marketing platforms (Google Analytics, Google Ads, or Floodlight).
If you want to try this out for yourself, I recommend heading over to Google’s GitHub repo. There, you can find a demo containing a sample dataset and instructions on how to configure the end-to-end pipeline.
Custom integration of Vertex AI into sGTM
While Google’s use case focuses on VBB, Phoebe’s real power lies in its flexibility—just like with the other Pantheon templates. Think of it as your gateway to bringing any Vertex AI model’s capabilities into your measurement infrastructure. By leveraging online prediction endpoints, you can supercharge your sGTM setup with predictive powers.
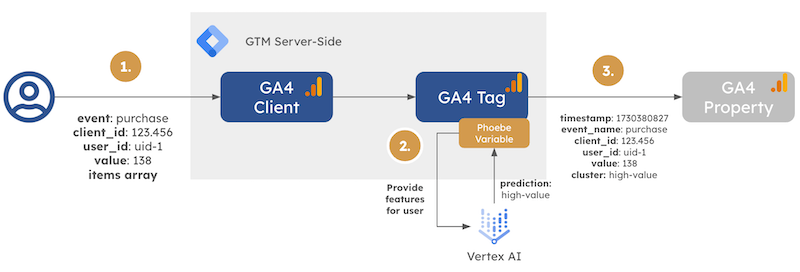 Phoebe High-level Architecture
Phoebe High-level Architecture
As I always strive to showcase something beyond the default to you, I did the same this time around.
So, instead of calculating a conversion value we pass to an advertising platform, we attempt to predict a user’s cluster (=audience) affiliation. The model itself is a clustering algorithm that, based on Recency-Frequency-Monetary features (days since last purchase, number of orders, lifetime value), assigns the user to a cluster (e.g., “New high-value customers”, “VIP customers”, “Mid-high frequency, high value, potentially churning”).
Note: I trained the model on a synthetic dataset in Google Colaboratory before I deployed the model file to Vertex AI and it’s merely for demonstration purposes. If you’re interested in the entire process from training a model on Vertex AI all the way on how to deploy it as an endpoint, which is a tad out of scope for this blog post, I recommend checking out GCP’s documentation.
In my custom implementation, the trigger for the Vertex AI real-time prediction is a purchase event containing user identifiers (client_id, user_id), the transaction value (138), and an items array.
I’m using the Phoebe variable template for audience prediction by combining real-time event data with user-level data stored in Firestore. I fetch the user data with the help of another sGTM Pantheon solution - Artemis. The Phoebe variable template is then attached to a GA4 tag triggered by the incoming GA4 purchase event. The variable configuration holds information about the model endpoint (1); it allows us to easily fetch item data from the event data (2) (not needed in my specific case) and add features to the endpoint request (3). Finally, we can configure a default value if the prediction attempt fails.
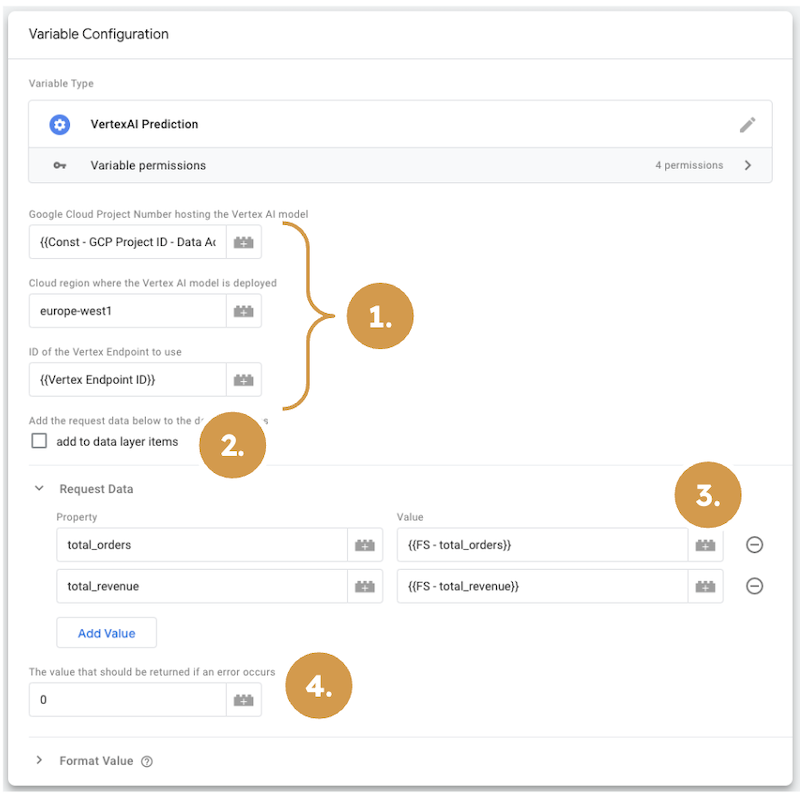 Phoebe variable configuration
Phoebe variable configuration
As you can see from the excerpt below from the variable template code, the variable combines the variable inputs about the model endpoint into a qualified URL to get online predictions and uses the request data input to build a payload. Eventually, the template uses the getGoogleAuth library to authenticate the outgoing HTTP request to Vertex AI.
// Build the URL for Vertex AI.
const url = "https://" + data.cloudLocation +
"-aiplatform.googleapis.com/v1/projects/" + data.projectNumber +
"/locations/" + data.cloudLocation + "/endpoints/" + data.vertexEndpointID +
":predict";
// Get Google credentials from the service account running the container.
const auth = getGoogleAuth({
scopes: ["https://www.googleapis.com/auth/cloud-platform"]
});
// The payload for VertexAI.
const postBodyData = {
"instances": predictionData,
"parameters": {}
};
const postBody = JSON.stringify(postBodyData);
...
// Make the request to Vertex AI & process the response.
return sendHttpRequest(url, requestOptions, postBody)
.then(success_result => {
logToConsole(JSON.stringify(success_result));
if (success_result.statusCode >= 200 && success_result.statusCode < 300) {
let result_object = JSON.parse(success_result.body);
let sum = 0;
result_object.predictions.forEach(num => { sum += num; });
return makeString(sum);
} else {
return data.defaultValueOnError;
}
})
.catch((error) => {
logToConsole("Error with VertexAI call to " + url + ". Error: ", error);
return data.defaultValueOnError;
});
The enhanced event data, including the cluster prediction (“high-value”), gets sent to the GA4 property, complete with all original parameters and AI-driven insights, unlocking building audiences based on the parameter.
Once again, the use case of serving real-time predictions is not completely new. I remember using a similar setup with a custom-built ML model that was pinged from a GTM web container in a project many years ago - not on Vertex AI, but on ML Engine (which was later integrated into Vertex AI). The difference here is that you can now make these requests from your own environment (sGTM) and don’t have to publicly expose the endpoint URL and the results to the end user. Furthermore, the solution provides a standardized way to integrate Vertex AI models into your sGTM setup, making it easier for you to leverage AI capabilities by simply using a variable template.
Note: While Phoebe is a terrific tool, I suggest you thoroughly check if you need an ML model for your use case. From my experience, a rule-based approach is often preferred as it’s a good way to get started and already gets you a long way. Keep in mind that hosting your model on Vertex AI and serving online predictions via the model endpoint does not come free of charge. As always with the sGTM pantheon solutions, make sure you develop a solid use case first before you jump into execution mode.
Dioscuri - The Gemini Integration
Now, on to the presentation of the last solution in this series. A solution that allows you to get responses from Google’s Gemini models. This time, the name of the solution is somewhat underwhelming - Dioscuri. The name is simply the Latin name “Gemini” translated into Greek. Nothing more, nothing less.
And yes, I know! It’s a boring name. Personally, I was just as disappointed as you are now when I came across it for the first time.
Google’s proposed use case is quite interesting though. Their team prompts Gemini to act as a virtual salesperson who has access to the user’s personal data, purchase history, and preferences. You can bring conversational AI capabilities into your measurement infrastructure through the Dioscuri variable template without the need for complex implementations. sGTM can then pass these messages back to the users’ browsers and display them to your liking.
As with all of the presented sGTM Pantheon solutions, they become even more powerful when combined. In Google’s suggested use case, they use Artemis to fetch user data from Firestore and then use that data to make the model generate highly personalized messages.
Again to actually work with the APIs by myself, I transferred the variable logic into a tag, which better suited my use case. The original variable template does the job just fine, if you prefer using it!
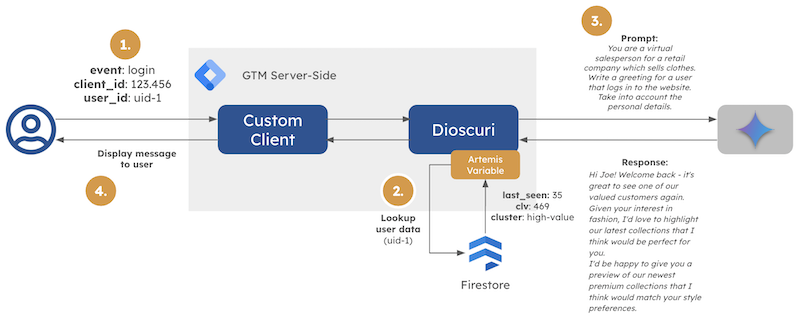 Dioscuri High-level Architecture
Dioscuri High-level Architecture
I eventually ended up with the above high-level architecture. I used a simple custom HTML tag to dispatch a request containing the user ID to sGTM upon user login. A lightweight client parses the incoming request and runs the container, where the Dioscuri tag is fired.
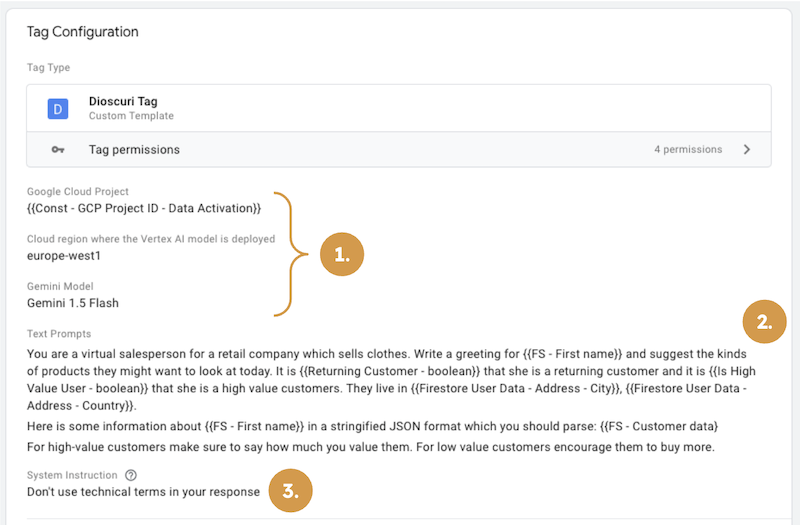 Dioscuri Tag Configuration
Dioscuri Tag Configuration
The tag itself (as well as the original variable-based solution) requires you to provide information about the GCP project and region, the model (1), a prompt of your choice (2), and further “system instructions” (3) to tune the LLM’s behavior.
In its original version the Dioscuri variable supports the 1.0 Pro as well as the 1.5 Pro version, but adding another model can quickly be done by adding another field to the dropdown menu in the template editor (s. the available Gemini model versions). If you want to use LLMs from other providers, you can adjust the template code to incorporate these.
In the example above, the prompts reference lookup variables from a Firestore database containing metadata about the user (e.g., first name, returning user boolean, address, product references, etc.). These data points allow the model to personalize the message to the user completely.
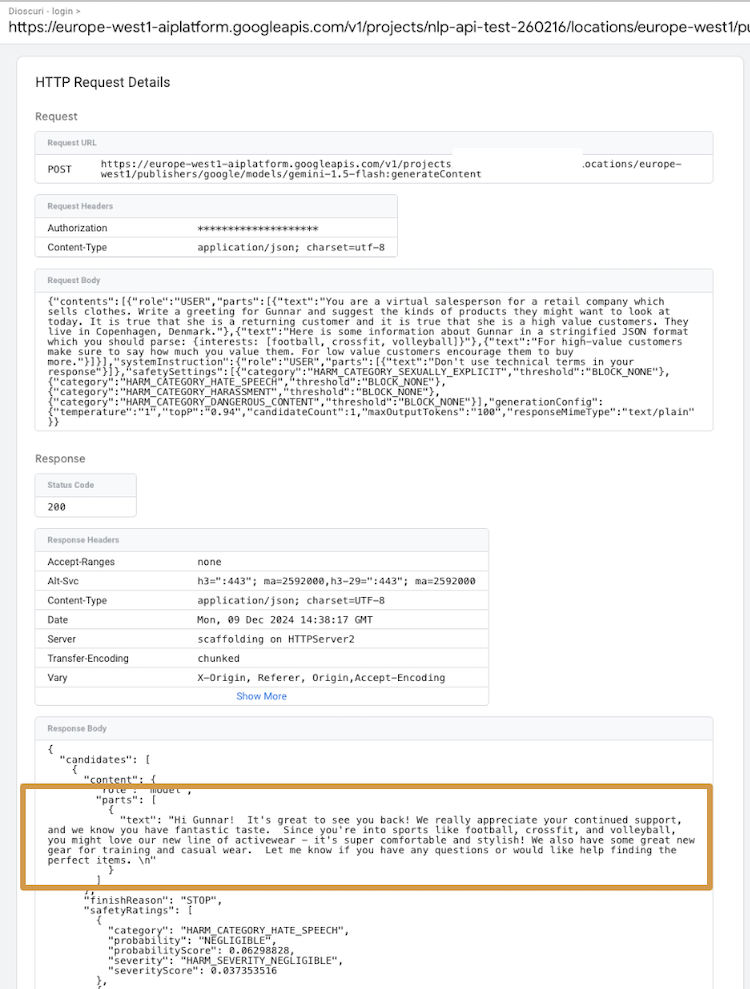 Dioscuri Model Response
Dioscuri Model Response
The tag passes on the prompt, including the user information, to the Gemini model of your choice. The model’s response contains the personalized message, which the tag then passes back to the client in the response body. Here, the custom HTML tag can extract the message and, e.g., populate a content placeholder in a pop-up banner that is shown to the user.
Note: As with the Phoebe solution, I advise you to use this technical solution with care. Not only does the use of the Gemini API come with a price tag, but you also need to make sure that the responses make sense and are meaningful. Furthermore, you should carefully consider where in the user flow you use this feature to avoid disrupting the journey. While the solution is an easy way to enhance the customer experience with AI-generated content, using dedicated service offerings for this kind of use case is the better solution.
Conclusion
The sGTM Pantheon solutions we’ve explored in this series - particularly Phoebe and Dioscuri - are powerful tools that can bring AI capabilities directly into your sGTM measurement infrastructure with comparatively low effort.
However, as with any technical solution, the key to success lies not necessarily in what’s technically possible but in what makes sense from a business perspective.
Hence, before diving into real-time ML predictions or AI-generated content, ask yourself three critical questions: First, do you need these real-time insights, or would a batch-processing approach be more cost-effective? Second, could more straightforward solutions (like rule-based systems) achieve similar results? Third, does it make sense that these solutions live in sGTM?
Always remember that just because we can enrich our data streams with AI-powered insights doesn’t always mean we should. The actual value of these solutions shows when they’re built on solid use cases that justify both the technical complexity and the associated costs—my advice: Start small, test thoroughly, and scale only what proves impactful for your business.
If you need help with your sGTM setup or have questions about the Pantheon solutions, feel free to reach out to me. I’m always happy to help you navigate the world of Google’s measurement infrastructure!
