
GTM Server-Side Pantheon - Part 1 - Tapping into the Power of Firestore
For those who have been following the evolution of GTM Server-Side (sGTM) and Google Cloud Platform (GCP) services, you might recall my early enthusiasm about the potential integrations. In a previous blog post about GTM Server-Side, I highlighted the prospect of enriching the clickstream data collected by GA4 with the help of other GCP services. Here is what I wrote about this way back in August 2020:
Furthermore, because the GTM container is executed in Google’s cloud environment, other GCP resources like BigQuery, ML Engine, and Cloud Functions will most likely be integrated soon. This will open up a lot of possibilities for advanced use cases involving machine learning and event-based analytics. Once this new GTM feature moves out of the beta phase after being improved based on feature requests and active community members’ contributions, even more possibilities will be available, significantly changing tracking implementations based on GTM.
Obviously, a lot has changed since then. Cloud functions are now Cloud Run functions, ML Engine as such doesn’t exist anymore and has been integrated into the Vertex AI platform, and GTM Server-Side has been officially released out of beta.
However, the vision of enriching the clickstream collected by GA4 with data provided by GCP services or feeding a company’s downstream systems in real time is still valid. In this series of blog posts, I want to invite you to join me on a mythological journey exploring the possibilities of integrating first-party data or triggering processes from sGTM using Firestore (this one), Pub/Sub (part 2), BigQuery & Google Sheets (part 3), and even Predictive Analytics & GenAI (part 4).
The state of GTM Server-Side
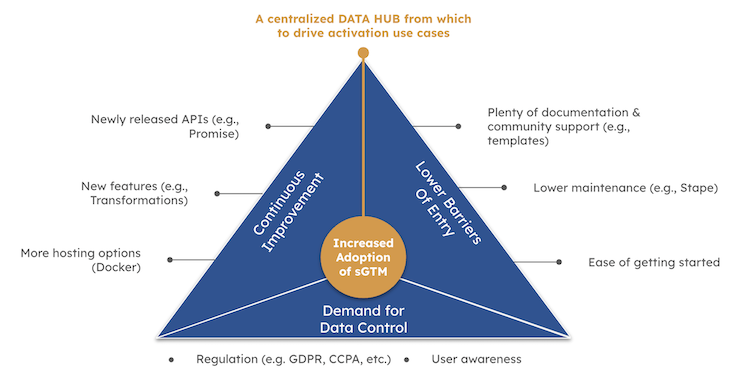
Since the release of sGTM, we have come a long way, and more and more companies have decided to opt into the technology to take advantage of the additional data controls for, e.g., data quality or privacy reasons. This trend has been powered by three main factors from my perspective:
- Google’s commitment to the technology and the continuous improvement of the service
- Companies’ and users’ increasing demand for data control and privacy compliance (especially in Europe and moving forward increasingly also in the US)
- Lower barriers of entry (more documentation and community support) and decreased need for maintaining server infrastructure (driven by players like Stape (first-mover), AddingWell, etc.)
While many companies have migrated their GA4 data collection to sGTM and might even use it to send data to other vendors, the technology’s potential is still not fully exploited. As is often the case in our line of work, most businesses have been focusing on the data collection part and have not yet fully embraced the possibilities for data enrichment and activation that are at their fingertips.
 Drivers for GTM Server-Side adoption
Drivers for GTM Server-Side adoption
The true power of an intermediary collection endpoint like sGTM lies in its ability to act as a data hub, where data from various, business-relevant sources can be transformed, combined, and sent to other systems in real time. In other words, you can gather different kinds of data (and combine them) and then send the widened data to the marketing vendors’ or your own systems as you see fit.
Standing of the Shoulders of Gods - The GTM Server-Side Pantheon
This is where the sGTM Pantheon comes into play. The Pantheon is a collection of (technical) solutions provided by Google, which allows one to easily get data from external services into sGTM via API calls or send data to external (GCP) destinations. The idea is to enhance sGTM’s native capabilities to allow businesses “to improve their reporting, bidding, audience management, and data pipeline management and processes” (s. Google’s documentation).
Admittedly, while not all solutions presented here are entirely new from a technical perspective, having these blueprints gathered in one place and explaining these wherever possible lowers the barrier of entry to take advantage of the full power of sGTM. So, this blog post series is my humble contribution to increasing adoption on a broader scale.
 How Dall-E thinks the Greek Pantheon looks like
How Dall-E thinks the Greek Pantheon looks like
Now, you might still ask yourself, why the “Greek Pantheon”? Well, Google decided to choose names from Greek mythology for each of the solutions. Just like the Greek gods, each solution has its own strengths and weaknesses, and they can be combined to create “god-like” data flows. Are you intrigued? I for sure was when I first stumbled upon the Pantheon and decided to keep the theme and mythology references for this series of posts.
Integrate Firestore into GTM SS - A match made in heaven
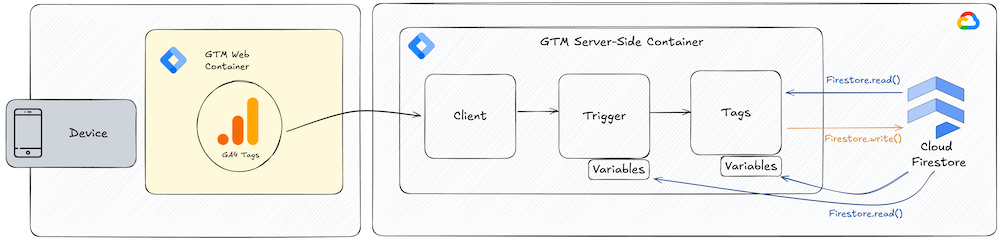
In the first part of this series, I want to focus on a set of solutions that are concerned with integrating Firestore into sGTM. GCP’s Firestore in the context of sGTM is particularly interesting, because Firestore and sGTM are a perfect match for real-time data enrichment and gathering. Firestore’s fast, scalable NoSQL database architecture allows for dynamic data lookups, while sGTM is the intermediary for collecting and processing first-party data.
Together, they enable businesses to enrich data streams on the fly, injecting further context into analytics, marketing, and personalization efforts. In the context of sGTM, Firestore is an additional storage option (alongside browser storage) that is fully controlled by the organization operating sGTM, that can be used to retrieve or store (potentially sensitive) first-party data, and that never exposes data to the browser (unless configured as such).
 Firestore integration into sGTM
Firestore integration into sGTM
GTM Server-Side and Firestore - Some technical background
Ever since the advent of the Firestore API for sGTM, it has become possible to tap into Firestore’s capabilities from within sGTM. In particular, the API comes with a set of methods allowing for reading, writing, and querying Firestore documents (using Firestore in Native mode):
Firestore.read- This function looks up data from a given Firestore document and returns a promise that resolves to an object returning the data.Firestore.write- This function writes whatever data you specify to a Firestore document or collection.Firestore.query- This function allows you to query a given collection and returns an array of Firestore documents that match specified query conditions.Firestore.runTransaction- This function allows reading and writing from Firestore atomatically.
Combined with the Promise API, these methods enable you to use these APIs asynchronously in variables (previously we had to build custom tags or clients), which can then be associated with any triggers or tags of your liking - making the integration of Firestore into sGTM a breeze (or least significantly easier).
Now, let’s examine the gods (and one demigod) of the Greek Pantheon who are concerned with Firestore integrations and look at some actual use cases.
Built-in Firestore Lookup Variable - Not so much a god, but a demigod nonetheless
The Firestore Lookup variable in sGTM may not have the full divine powers of the Greek Pantheon (and, therefore, is not part of it), but I certainly consider it a reliable demigod. It offers a powerful way to enrich your data streams, especially when you need a database with lightning-fast read/write operations to provide real-time data lookups and widen the information available to your marketing tools or other systems.
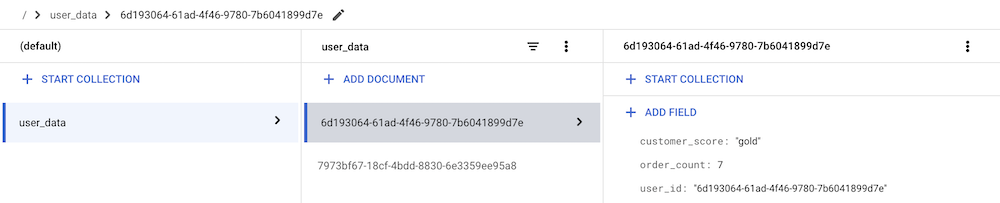
To provide you with a practical example of how to widen the data available in GA4 with additional user data stored in Firestore, I created a simple “user database” in Firestore with the following structure and entries:
 Exemplary Firestore User Database
Exemplary Firestore User Database
As you can see, for each user in the database, we store the user_id, the customer_score, and the order_count. The user_id is the unique identifier for each user, while the customer_score and order_count are attributes that we want to use to enrich the data sent to GA4. The customer_score could be used to segment users based on their value to the business, while the order_count could be used to identify loyal customers or to trigger tags conditionally. In general, we unlock activation use cases in our downstream systems if we can get these data points (or similar ones) in there using the Lookup variable.
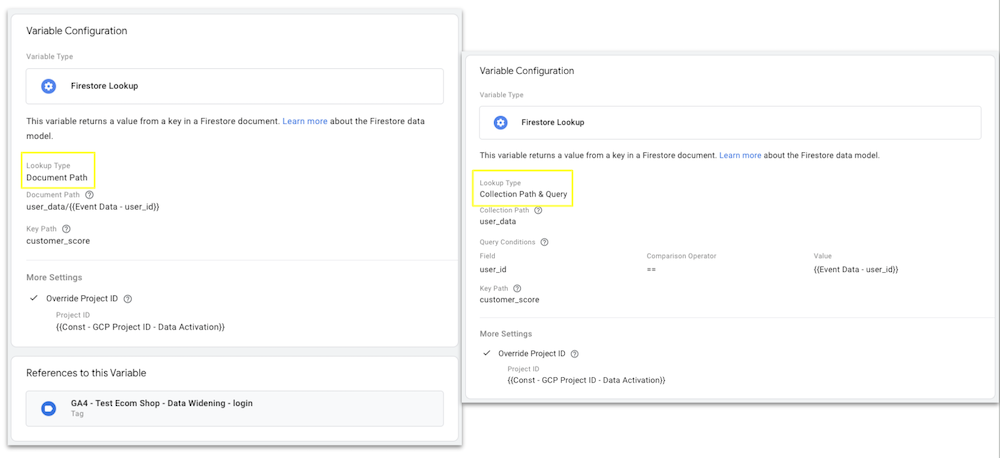
The Firestore Lookup variable is designed to fetch data from Firestore documents, which are structured in collections (in case you’re unfamiliar with the Firestore data model, you can read more about the Firestore data model). Its flexibility allows for two types of lookups: direct document path or collection-based query. When using the direct path method, you can pull specific documents by providing their exact location in the database (e.g., user_data/Event Data - user_id). This is the fastest approach, as it immediately fetches the desired document without further filtering. In the example below, the variable would retrieve the user_data document with the user_id matching the value from the GA4 event data and return the user’s customer_score.
 The Firestore Lookup Types in GTM Server-Side
The Firestore Lookup Types in GTM Server-Side
Furthermore, Firestore Lookup variables allow for collection-based queries. By querying collections based on document fields (e.g., user_database where user_id == User ID, which in this specific case requires that the user_id is a field in the document), you can dynamically search for documents that match your criteria. This approach is practical when the exact document path is unknown, but certain identifying features are available. In all cases you have to make sure that your App Engine or Cloud Run default service account has Cloud Datastore User permissions to read from Firestore.
Once the correct document is found, the variable requires you to extract specific values (which can also be complex objects) by specifying a Key Path—like customer_score. In our case, the user’s customer_score value can be passed on as a user property to GA4 to unlock analysis use case or for audience building, which can then be shared within the Google Marketing Platform (GMP) for retargeting or look-alike audiences. But like with all variables, you can use the retrieved data in both tags and triggers of your sGTM setup to either fire tags conditionally or to enrich the data sent to all sorts of marketing vendors.
Although not quite “god-like,” the Firestore Lookup variable offers an efficient tool for extending the power of sGTM with real-time data from Firestore, proving its worth as a critical component in the sGTM data integration stack.
For those of you who are interested in a more detailed guide on how to set up the Firestore Lookup variable in sGTM, I recommend heading over to Simo Ahava’s extensive blog post.
Artemis - The Huntress for Data
Just as the goddess Artemis was known for her precision and skill in the hunt, the Artemis solution does incredibly well in tracking down and retrieving valuable data from Firestore.
So, what makes Artemis the goddess different from the built-in Firestore Lookup variable, which I demoted to a demigod?
Well, unlike the built-in Firestore Lookup variable, which focuses on fetching individual document attributes (e.g., the customer_score value), Artemis takes it a step further by fetching entire documents and allowing you to extract multiple values from a single API call. This makes the Artemis solution an efficient tool to optimize cost and performance by reducing the number of API calls needed to retrieve data from Firestore. So, if you need to get an entire Firestore document or plan to extract multiple values from a single document - for example, multiple user or product characteristics - Artemis is the goddess you should call upon.
 Artemis Variable Templates in GTM Server-Side
Artemis Variable Templates in GTM Server-Side
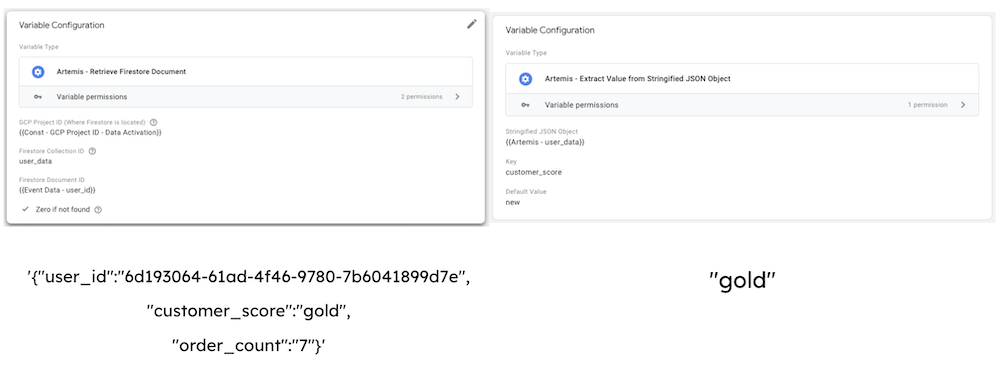
From a technical perspective, the Artemis solution comes with two variable templates: The first is designed to fetch an entire Firestore document, while the second one allows you to extract specific values from that document using a Key Path.
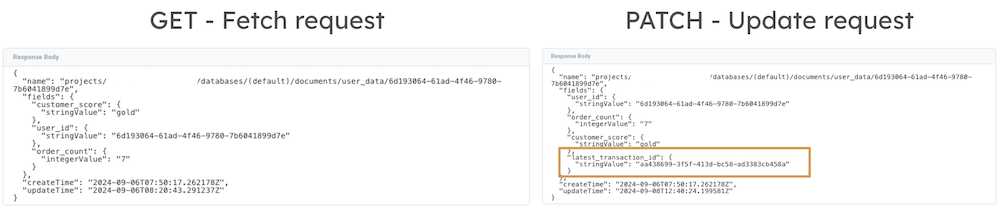
The first variable template uses the Firestore.read and the Promise APIs to asynchronously fetch data from Firestore. For the setup, all you have to do is provide the GCP project ID and enter the collection name and the document ID from which to retrieve the document. Eventually, the variable returns a stringified JSON object with the document’s data from a single API call. In my example, the variable Artemis - user_data variable would return the following JSON object for the document with the ID 6d193064-61ad-4f46-9780-7b6041899d7e:
'{"user_id":"6d193064-61ad-4f46-9780-7b6041899d7e", "customer_score":"gold", "order_count":"7"}';
The second variable template takes the stringified JSON object from a variable instance of the first variable template as an input and extracts a specific value using the provided key. This lets you pinpoint the needed data and pass it on to your tags or triggers in sGTM.
In my example, the second variable template would extract the customer_score value from the stringified JSON object and return "gold".
With Artemis, you can seamlessly integrate Firestore with sGTM to power tailored marketing strategies using first-party data stored in the cloud. Artemis allows you to hunt for data like its namesake, making it a valuable asset in your sGTM data integration stack.
Soteria - The Safeguard of Data
Soteria, the goddess of safety, deliverance, and protection, is for sure one of the lesser-known Greek deities. But, the Soteria solution shouldn’t suffer the same fate, as I see it as a crucial part of the GTM Server-Side Pantheon that can help you get more out of your marketing spend in GMP.
Value-based bidding (VBB) is one of the most powerful tools in the GMP, as it allows you to optimize your bids based on the value that each conversion brings to your business. However, to use VBB effectively, you need to provide Google Ads with the conversion value for each conversion event. Obviously, the closer the conversion value is to the actual contribution to your business goals, the more you get out of marketing efforts.
Traditionally, most companies calculate this value based on the revenue generated by the conversion event, but only in some cases is the revenue the relevant conversion value. Digitally mature businesses have realized that the actual conversion value can be more complex and might depend on various factors, such as the return rate, discounts, or profit margin.
Before the advent of sGTM, it was pretty challenging to calculate the conversion value dynamically and send it to GMP in real-time. Hence, I’ve seen companies going down one of two paths: either they retrieved sensitive data like profit margins (e.g., by requesting that data through an open API) and exposed it to the dataLayer, or they reverted to adjusting the conversion value in batch using the GMP APIs. Both approaches have their downsides: the first exposes sensitive data to the browser, while the second is not real-time and might negatively impact bidding due to the delay in updating the value.
 Soteria Architecture and Data Flow diagram
Soteria Architecture and Data Flow diagram
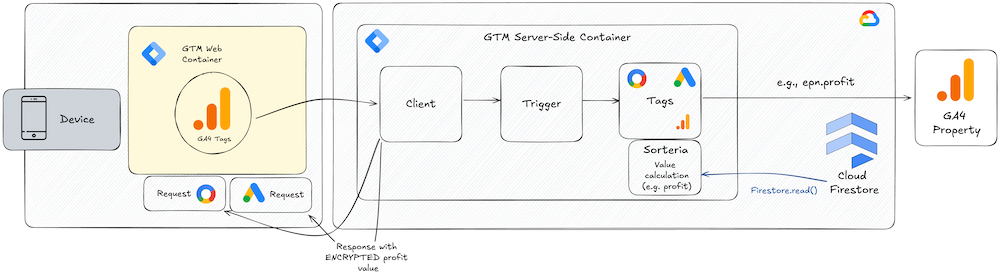
Soteria, the goddess of safety, solves this problem. She allows you to calculate the conversion value dynamically in sGTM and send it to GMP, GA4, or other vendors in real time without exposing sensitive data to the browser. Once again, the solution is based on the Firestore.read and Promise APIs and comes with its own variable template to fetch the necessary data from Firestore.
The solution is designed to work out of the box with the incoming GA4 purchase event data, which contains the item_id for each product in the transaction. The variable looks up the profit value for each product and calculates the total profit-based conversion value. The newly computed conversion value is then passed to the Conversion Value or Revenue setting in the respective Google Ads or Floodlight Sales tags.
Now, don’t all Google Ads and Floodlight tags triggered in sGTM result in a client-side request to eventually send the data to the platforms? How can you claim that the profit value (or other sensitive data) is not exposed in the user’s browser?
Well, the answer is simple: Both tag types actually encrypt the conversion value before passing it back to the browser, so the data is never exposed to the user. This is a crucial point to understand, as it allows you to send sensitive data to GMP without compromising control over your data.
 Exemplary Firestore Database Setup for Soteria
Exemplary Firestore Database Setup for Soteria
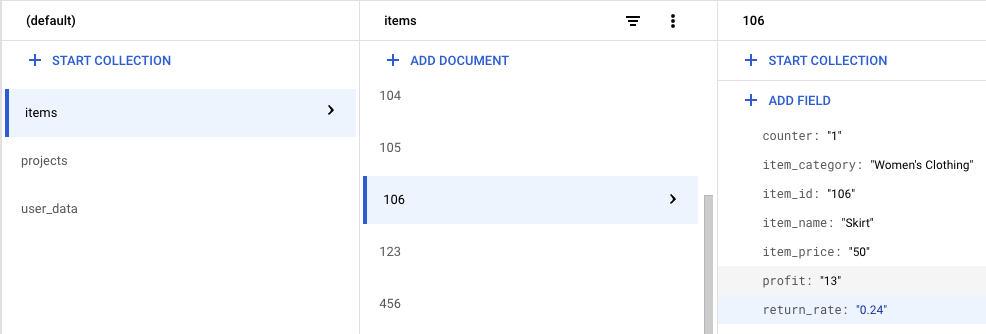
The technical requirements for the Firestore database are fairly straightforward. All you need is a collection with the item_id as the document ID and the profit value (or others like return_rate) as an attribute. The item_id is then used to look up the profit value for each product in the transaction.
Let’s examine the actual variable template and its functionalities to “connect” it to the exemplary “items” database.
 Soteria Variable Template in GTM Server-Side
Soteria Variable Template in GTM Server-Side
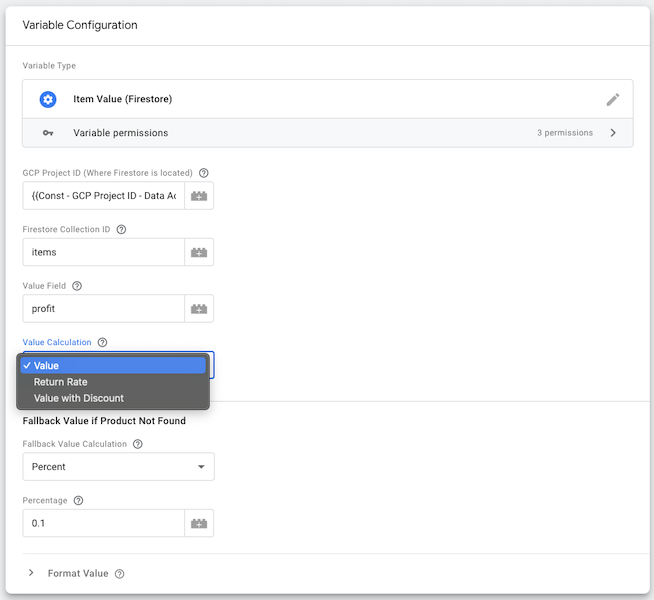
As you can see, the Soteria solution supports three different calculation methods:
- Value
- Return rate
- Value with Discount
Based on the chosen method, the calculations include the profit value (Firestore), the return_rate (Firestore), the quantity of the product sold (retrieved from GA4 purchase event’s items array), and the discount. Under the hood, the following formulas are used to calculate the conversion value based on the selected method:
conversion_value = profit * quantity; // "Value" setting
conversion_value = (1 - return_rate) * profit * quantity; // "Return Rate" setting
conversion_value = (profit - discount) * quantity; // "Value with Discount" setting
In case a product cannot be found in the database, the template allows you to specify three different fallback mechanisms using values from the original purchase event data:
- Zero
- Revenue
- Percent
conversion_value = 0; // "Zero" setting
conversion_value = price * quantity; // "Revenue" setting
conversion_value = price * percent * quantity; // "Percent" setting, with the variable being the custom "FallBack Percentage"
If you haven’t already, you should definitely consider using Soteria or at least test it out—summoning her is well worth it!
Based on numerous Google case studies and from experience with my own clients, I’ve seen it significantly improve the performance of their GMP campaigns, simply because the conversion value is now more closely aligned with the actual business value. As always, the results can be impressive when operating at the sweet spot of data, tech, and actual business use cases.
Hephaestus - The God of Fire(store)
As a smithing god, Hephaestus made all the weapons of the gods. He served as their blacksmith and was considered the god of craftsmen, metallurgy, and fire. Moreover, Hephaestus was the only Olympian god to do actual work, which is also fitting for the Hephaestus solution, as it allows you not only to lazily read data Firestore but also actively write to it.
 Hephaestus tag template settings
Hephaestus tag template settings
Unlike the previous solutions, Hephaestus comes in the form of a tag template. This template requires you to specify the GCP project ID, the collection name, the document ID, and the data you want to write to Firestore. The tag template uses the Firestore.read, Firestore.write, and the Promise APIs to asynchronously write data to Firestore, allowing you to store and update information in real-time.
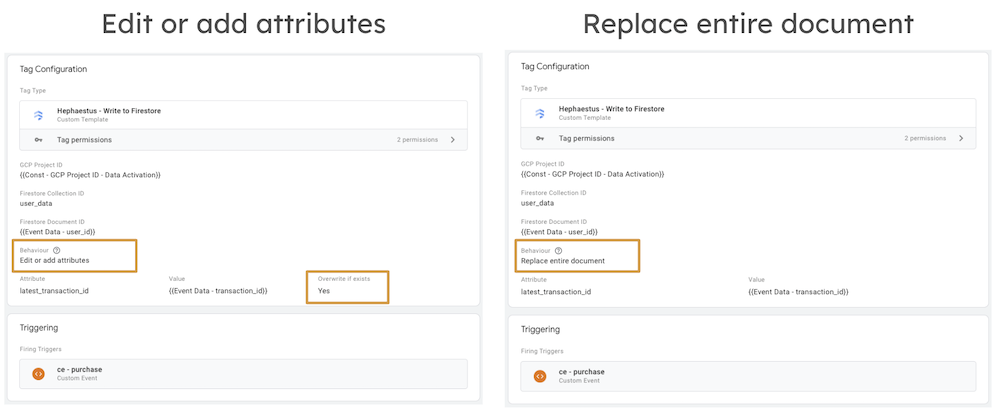
In the tag, you further specify which attributes (key-value pairs) you want to write to Firestore and whether you want to replace the existing document with the latest data or merge the new data with the existing one.
 Hephaestus requests for “Edit or add attributes” settings
Hephaestus requests for “Edit or add attributes” settings
In the example above, which uses the “Edit or add attributes” setting, the tag would, therefore, first read the existing document from Firestore, then update the latest_transaction_id attribute with the value from the GA4 event data, and finally write the updated document back to Firestore. On the other hand, the “Replace entire document” setting would replace the entire document with the new data, which can be useful when storing only the latest user interaction data.
Hephaestus can be a true asset if you want to maintain an up-to-date user profile in Firestore that can be edited in batch from the backend or in real-time with data from GTM. If this fits your use case, you could store the user’s last interaction with your website, the previous product they viewed, or the last page they visited and bring in fresh data from your CRM every night. Accessing an enriched user profile is valuable for all your personalization or targeting efforts and you can easily combine the Hephaestus solution with e.g. built-in Firestore lookups or Artemis.
As I mentioned before, the principles used for these Google solutions have been introduced previously. Hence, if you are interested in this topic, I can also recommend checking out Stape’s Firestore Writer tag template that has similar functionality to Hephaestus but comes with more bells and whistles. For example, it allows you to write the entirety of the available event data to Firestore, can quickly add timestamps, etc. - and it’s also a great starting point for building custom tags.
Nice to know: I am currently working on a modified Hephaestus tag template that maintains a real-time count of, e.g., item purchases, event counts, etc., to build a simple analytics system where the server container writes the hit stream data to Firestore and a dashboard app hosted in Cloud Run reads and visualizes it. See the below video to get an idea of the putcome. Stay tuned for more on this!
Conclusion
Yes, I know… This is another lengthy blog post, but I hope you enjoyed the journey through the Greek Pantheon of GTM Server-Side solutions. Midway through the post, I realized that cramping all the solutions into one post would be too much, so I split it into five parts. In this first part, we explored the possibilities of integrating Firestore into sGTM using the Artemis, Soteria, and Hephaestus solutions.
We learned how to fetch entire documents, extract specific values, and write data to Firestore, enabling businesses to enrich their data streams and enhance their marketing strategies. In the next part of this series, I’ll discuss how to integrate BigQuery with sGTM.
Even if the out-of-the-box templates outlined in this post do not meet your requirements 100%, they can be a great starting point for building custom tags or variables that fit your specific use case. The most important part I want to convey is how much more potential is in your data if you combine it cleverly. Firestore and sGTM are mere vehicles that allow you to do just that, giving you the power to rethink and shape your data strategy.
If you are unsure about which use cases could help you meet your business goals, require more customized functionality, or want to implement one of the described approaches, feel free to contact me; I am always happy to help.
I hope you enjoyed reading this blog post as much as I did writing it. If you have any questions or feedback, please get in touch with me on LinkedIn or via Email. Until next time, happy tracking!
Book a meeting with me: Calendly